【備忘録】pd.merge(join) したらデータが増えた話
こんにちは、やもり(yamori-tech)です。
備忘録として「pd.merge したらデータが増えた話」について書こうと思います。
結論としては、drop_duplicates(['hoge'], keep='last')を指定することで、right側のデータの最新のレコードを一意(ユニーク)とすることで、解決します。
df3 = df2.sort_values('update_time').drop_duplicates(['id'], keep='last')
何があったの?
データ処理で別々のテーブルデータ(df1, df2)がある時、df1 レコードに df2 レコードを merge, join で結合していたら、データが増えました。
詳細状況としては、例えばですが、df1, df2 データが下記のようにある時


下記条件で結合されたデータがほしいとします。
- id でレコード結合したい
- df1 のレコード数は変えたくない
これを実現するため join, merge を利用しますが、単純にやるとレコードが増えます。
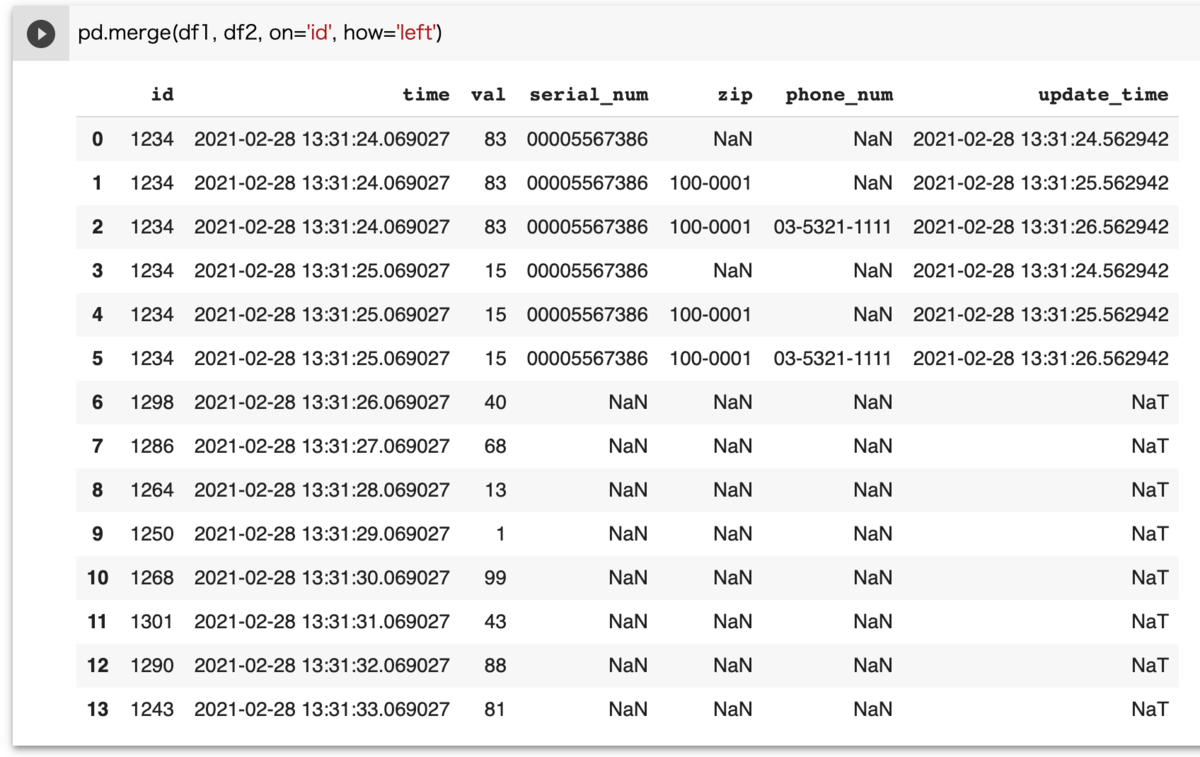
join(merge) の使い方として、レコード数を維持したい側を left(or right)とした時、連結される側 right(or left)は一意(unique)でなくてはならない。
つまり、多 対 多 のデータで連結してしまうと、データ増えちゃうよね。。ということですね。(そらそうじゃ。。)
すなわち、結合される側が「多」であるならば一意にのデータセットにしなくてはいけない; 今回でいうと df2 の id を一意にしなくてはなりません。
df2 は update_time が付与されているので、各 id のupdate_time の最新(最古)を一意な id として取り出したほうが良さそうです。
※状況によるため、その時時で一意にする条件は変わりますが、単純に最新データ利用ならば、上記対応でよさそう。
解決手段
update_timeをソートし時系列で並べたあと、一意な最新(最古)idを取り出す、ができればやりたいことは実現できます。 時系列は sort_values で良いとして、「一意な最新(最古)idを取り出す」をどうするか、ですが…。
やり方はたくさんあると思いますが、今回は drop_duplicates を利用しました。 一意に取り出したいカラムを subset(省略可)で指定し、keep オプションで last 指定してあげると、最後に追加された行を取り出してくれます。
というわけで、スクリプトと実行結果は以下になります。
df3 = df2.sort_values('update_time').drop_duplicates(['id'], keep='last') df3

df3 が新しくできたので、 df1 と df3 を結合すると。。

ほしかった状態になりました。 ※ join でも同じなので省略。
最終的なソースコードは以下。
import pandas as pd import datetime as dt import random import numpy as np df1 = pd.DataFrame(index=[i for i in range(0, 10)], columns=['id', 'time', 'val']) now_time = dt.datetime.now() df1.loc[:, 'id'] = [1235 + random.randrange(0, 100) for i in range(10) ] df1.loc[0, 'id'] = 1234 df1.loc[1, 'id'] = 1234 print('-- result df1 --') display(df1) df1.loc[:, 'time'] = [now_time + dt.timedelta(seconds=i) for i in range(10) ] df1.loc[:, 'val'] = [random.randrange(0, 100) for i in range(10) ] now_time_2 = dt.datetime.now() df2 = pd.DataFrame(index=[i for i in range(0, 3)], columns=['id', 'serial_num', 'zip', 'phone_num', 'update_time']) df2.loc[:, 'id'] = 1234 df2.loc[:, 'serial_num'] = '00005567386' df2.loc[:, 'zip'] = '100-0001' df2.loc[0:0, 'zip'] = np.nan df2.loc[:, 'phone_num'] = '03-5321-1111' df2.loc[0:1, 'phone_num'] = np.nan df2.loc[:, 'update_time'] = [now_time_2 + dt.timedelta(seconds=i) for i in range(3) ] print('-- result df2 --') display(df2) print('-- result merge [df1, df2] --') display(pd.merge(df1, df2, on='id', how='left')) print('-- result df3 --') df3 = df2.sort_values('update_time').drop_duplicates(['id'], keep='last') display(df3) print('-- result merge [df1, df3] --') pd.merge(df1, df3, left_on='id', right_on='id', how='left')