【備忘録】8桁のstr型数字 00000000 を pd.read_csv で読み込んだら 0.0 になる罠にハマった話
こんにちは、やもり(yamori-tech)です。
備忘録として「8桁のstr型数字 00000000 を pd.read_csv で読み込んだら 0.0 になる罠にハマった話」について書こうと思います。
結論としては、dtype=object を指定することで、空欄を維持したまま csv を読み込むことができます。
>|python|
pd.read_csv('hoge.csv', dtype=object, encoding='utf-8')
||<何があったの?
データ処理のため、データベースからデータを一時的にごっそりcsvファイル(hoge.csv)にしたあと、処理しやすくするため、v1.csv, v2.csv と単純に分割していました。そんな時…。
- DBにこんなデータがあったとき。。
id col1 col2 col3 1 11 0000 0000000 2 15 0000 0000000 3 14 0000 0000000 4 17 0000 0000000 5 21 0000 0000000
- DB -> hoge.csv へダウンロード、この時点で hoge.csv の col3 には 00000000(文字列)で格納
- hoge.csv を v1.csv、v2.csv などへ分解すると、v1.csv、v2.csv の col3 は
0(int) で保存
になる罠にハマってしまいました。。
0000(文字列)は、0000 として エクセル上では 保存されているのになぜなのか?
※ 環境によっては、0000 も 0 になるようです。

色々試したのですが、業務用環境では、read_csv を使って、col3 に格納されているような 8桁の0の文字列「00000000」を読み込むと、0 として認識してしまうようでした。
処理上の制限と解決手段
処理上の制限として、
- 00000000 の文字列があるデータファイルが存在する前提で、レガシースクリプトが動いている
- 時間の関係で、レガシースクリプトは改修できない
- そもそもデータベースと同じ値を再現できていない時点で問題あり
ということで、00000000 のまま出力する必要がありました。
解決手段としては、
- col2, col3 を str 変換し、replace してしまう
→ しかし、空部分を、None、NaN等で変換してしまう
→ レガシースクリプトでは、空部分は空として与えなくてはならない
というわけで、公式ドキュメントを再度読むと。。


適切なna_valuesを維持するために、dtype に object か str を指定したら良いよ!と書いてあるので、指定してみると。。

想定していた出力になりました。
dtype は 辞書型にすることで、カラムごとに読み込み形式を指定することもできます。
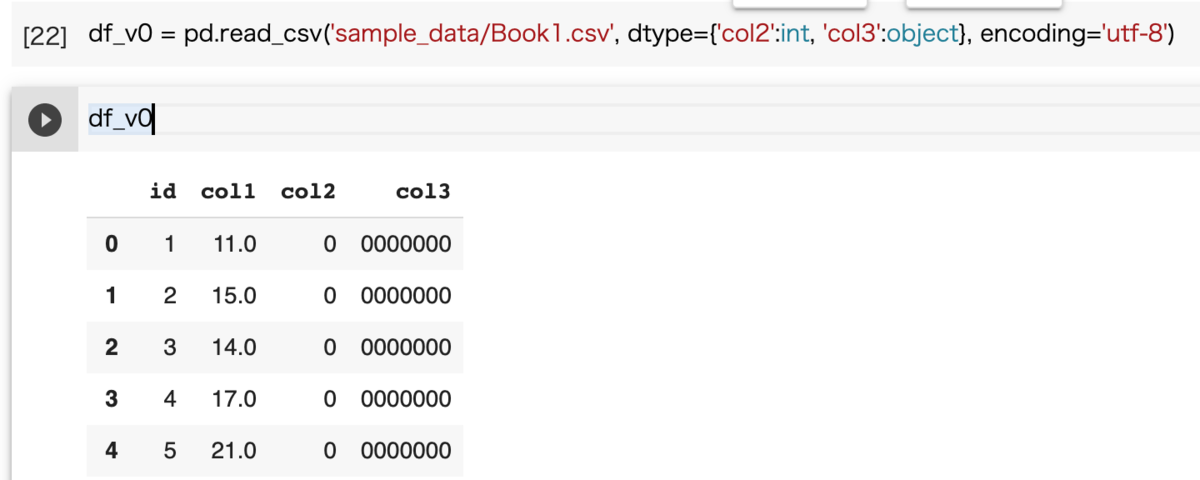
00, 001 等を読み込むために、read_csv で dtype = str or object を今後は使っていこうと思います。